
Publications
IEEE L-CSS 2023
Data-Driven Predictive Control Using Closed-Loop Data: An Instrumental Variable Approach
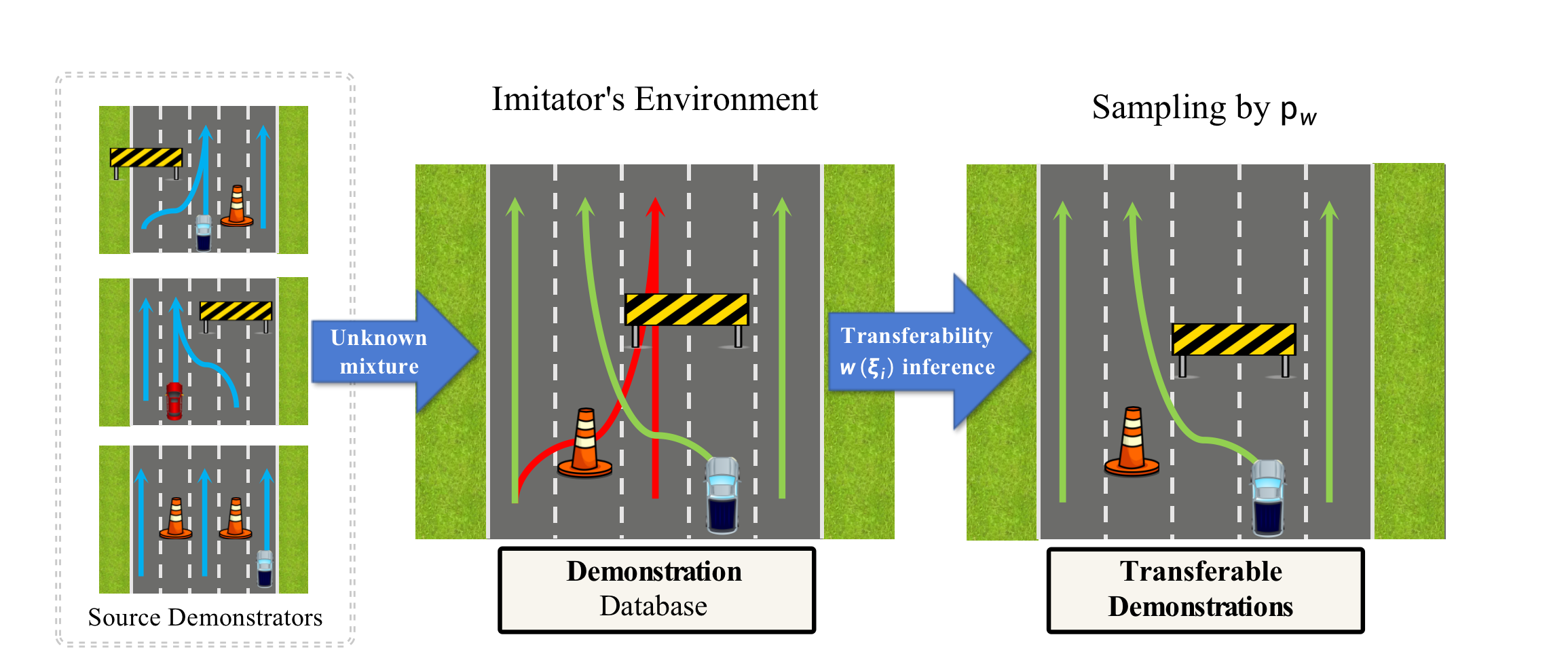
NeurIPS 2022 · Spotlight
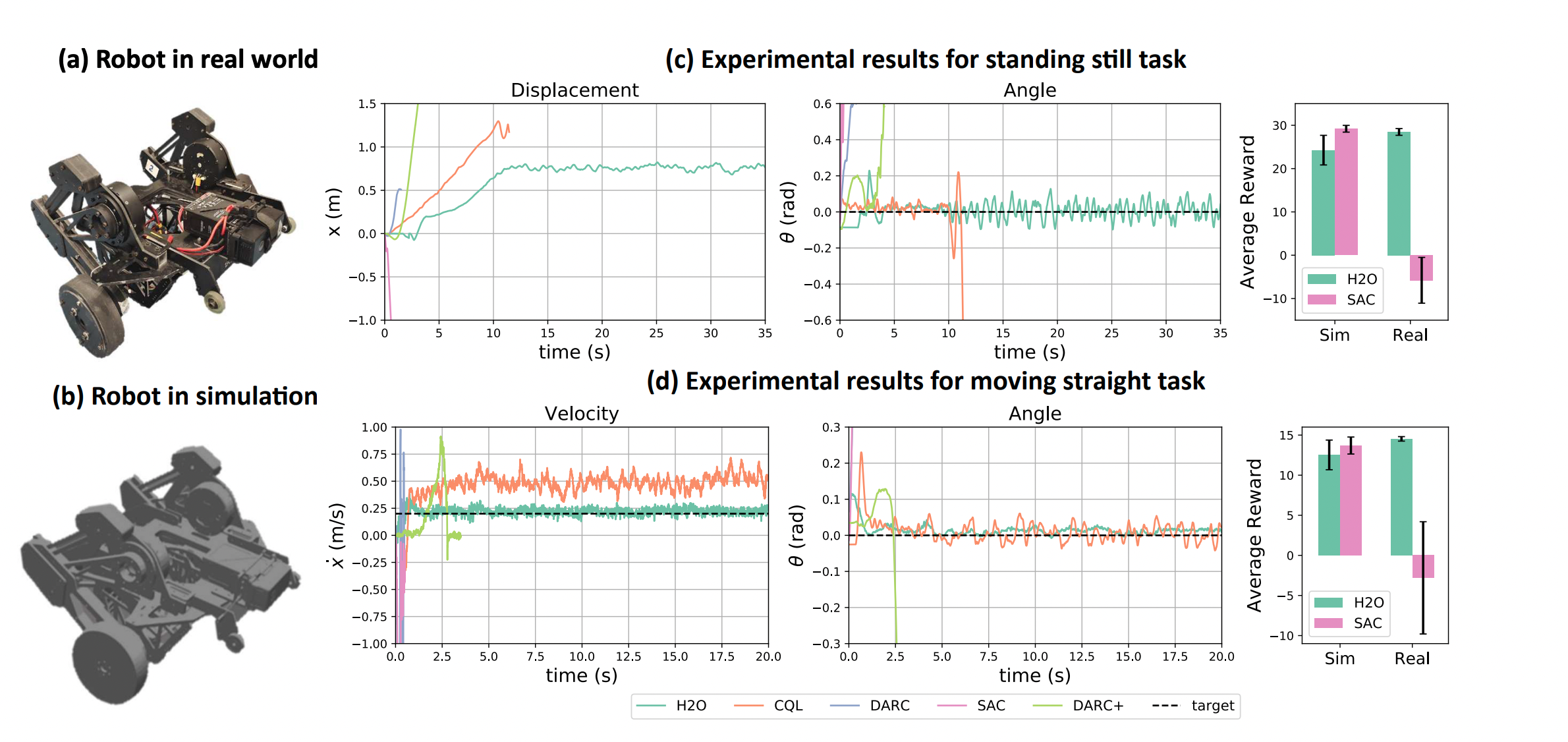
When to Trust Your Simulator: Dynamics-Aware Hybrid Offline-and-Online Reinforcement Learning
Data-Driven Predictive Control Using Closed-Loop Data: An Instrumental Variable Approach
When to Trust Your Simulator: Dynamics-Aware Hybrid Offline-and-Online Reinforcement Learning